
Overview
Welcome to the HPC-accelerated AI project (enhanced from the formerly known High-Performance Deep Learning project), created by the Network-Based Computing Laboratory of The Ohio State University. The availability of large data sets coupled with modern HPC technologies have been fueling growth in distributed training and distributed inference. The HPC-AI project introduces a vendor neutral software stack (as shown below) to implement high-performance and scalable distributed training and inference using the popular MVAPICH-Plus MPI-based communication library supporting excellent scale-up and scale-out with modern CPUs, GPUs, and interconnects. The objective of the HPC-AI project is to exploit modern HPC technologies to provide high-performance and scalable solutions for foundational model training, agentic workflows, and reinforcement learning. The HPC-AI packages are being used by more than 90 organizations worldwide in 21 countries (Current Users) to accelerate Deep Learning and Machine Learning applications. As of Jun '26, more than 6,350 downloads have taken place from this project's site. The HPC-AI project contains the following packages.
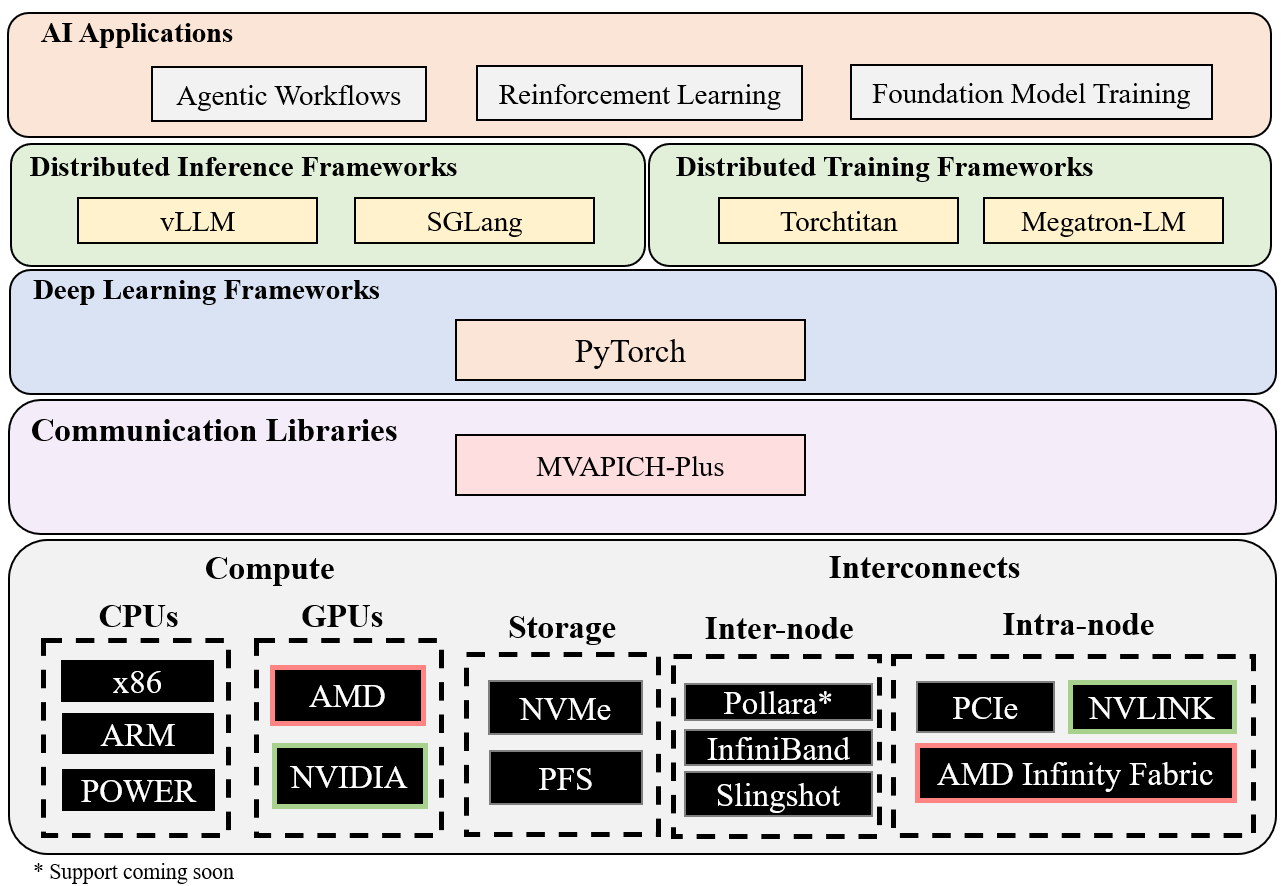
HPC-AI: An MPI-Driven AI Software Stack with MVAPICH-Plus
The HPC-AI software suite version 1.0 is a high-performance deep learning software stack built on the MVAPICH-Plus GPU-aware communication backend. HPC-AI integrates state-of-the-art distributed training and inference frameworks with optimized MPI communication on modern HPC clusters powered by GPUs and high-performance interconnects.
The 1.0 release of the HPC-AI stack introduces the following key features:
- Full-stack integration of Training and Inference Frameworks: PyTorch, DeepSpeed, vLLM, and SGLang with MVAPICH-Plus
- The NOWLAB PyTorch features
- Native PyTorch Distributed Data Parallel (DDP) training with MPI backend
- Efficient large-message collectives (e.g., Allreduce) on various CPUs and GPUs
- GPU-Direct Ring and Two-level multi-leader algorithms for Allreduce operations
- Support for fork safety in distributed training and inference environments
- Efficient large message collectives in MVAPICH-Plus 4.1 and later
- Open-source framework builds with advanced MPI backend support
- Advanced inference decoding methods ( MAC-Attention ) and communication runtimes (MCR-DL)
- Vendor-neutral stack with competitive performance to GPU-based collective libraries (e.g., NCCL, RCCL)
- Battle tested on modern HPC clusters (e.g., OLCF Frontier, TACC Vista, SDSC Cosmos) with up-to-date accelerator generations (e.g., AMD, NVIDIA)
- Compatible with
- InfiniBand Networks: Mellanox InfiniBand adapters (EDR, FDR, HDR, NDR)
- Slingshot Networks: HPE Slingshot
- GPU&CPU Support:
- NVIDIA GPU A100, H100, GH200
- AMD MI250X, MI300A GPUs
- Software Stack:
- Python [3.x]
- CUDA [12.x] and Latest CuDNN
- (NEW)ROCm [7.x]
- (NEW)PyTorch [2.10.0]
- Training & Inference Frameworks:
- (NEW)DeepSpeed, vLLM, SGLang
For instructions on getting started with HPC-AI, please refer to the HPC-AI Quick Start
PyTorch Native DDP Performance on MVAPICH-Plus
MPI4DL v0.6
MPI4DL v0.6 is a distributed and accelerated training framework for very high-resolution images that integrates Spatial Parallelism, Layer Parallelism, and Pipeline Parallelism.
- Based on PyTorch
- (NEW)Support for training very high-resolution images
- Distributed training support for:
- Layer Parallelism (LP)
- Pipeline Parallelism (PP)
- Spatial Parallelism (SP)
- Spatial and Layer Parallelism (SP+LP)
- Spatial and Pipeline Parallelism (SP+PP)
- (NEW)Bidirectional and Layer Parallelism (GEMS+LP)
- (NEW)Bidirectional and Pipeline Parallelism (GEMS+PP)
- (NEW)Spatial, Bidirectional and Layer Parallelism (SP+GEMS+LP)
- (NEW)Spatial, Bidirectional and Pipeline Parallelism (SP+GEMS+PP)
- (NEW)Support for AmoebaNet and ResNet models
- (NEW)Support for different image sizes and custom datasets
- Exploits collective features of MVAPICH2-GDR
- Compatible with
- NVIDIA GPU A100 and V100
- CUDA [11.6, 11.7]
- Python >= 3.8
- PyTorch [1.12.1 , 1.13.1]
- MVAPICH2-GDR = 2.3.7
- MVAPICH-PLUS = 3.0b
Announcements
HPC-AI 1.0 (a vendor neutral stack) with support for PyTorch 2.10.0, built on top of the MVAPICH-Plus MPI back-end, DeepSpeed, vLLM, and SGLang, providing distributed training and inference without the need of any vendor supported collective communication library. This new stack aims to exploit modern HPC technologies to provide high-performance and scalable solutions for foundational model training, agentic workflows, and reinforcement learning and is available. [more]
HiDL 2.2 (a vendor neutral stack) with support for PyTorch 2.9.1 and later versions, built on top of the MVAPICH-Plus MPI back-end, providing large-scale Distributed Data Parallel (DDP) training for clusters with NVIDIA and AMD GPUs and without the need of any vendor supported collective communication library is available. [more]
ParaInfer-X v1.0 with MPI and NCCL-based support for fast parallel inference of various large language models (GPT-J and LlaMA), persistent model inference stream, temporal fusion/in-flight batching of multiple requests, multiple GPU tensor parallelism, asynchronous memory reordering for evicting finished requests, and support for float32, float16, bfloat16 for model inference is available. [more]
MPI4DL 0.6 with support for distributed and accelerated training framework for very high-resolution images that integrates Spatial Parallelism, Layer Parallelism, and Pipeline Parallelism is available. [more]
MPI4cuML 0.5 (based on cuML 22.02.00) with support for RAFT 22.02.00, C++ and Python APIs, built on top of mpi4py over the MVAPICH2-GDR library, handles to use MVAPICH2-GDR backend for Python cuML applications (KMeans, PCA, tSVD, RF, and LinearModels) is available. [more]
Partnership and contribution to the NSF-Awarded $20M AI-Institute on Intelligent CyberInfrastructure (ICICLE). Details.

